I recently came across a paper called Why Language Models Hallucinate by Adam Tauman Kalai, Ofir Nachum, Santosh Vempala, and Edwin Zhang. I wanted to write down what I understood from it in simple terms, because the ideas seemed important and also explained something I had noticed while using AI tools.

TL;DR
- AI makes confident but wrong guesses because of how it’s trained and tested
- Training limits cause some errors by default
- Testing makes it worse by giving zero points for “I don’t know”
- Guessing is always rewarded more points than honesty
- To fix this, scoring needs to value uncertainty too
What is a hallucination in AI?
When people talk about AI hallucinations, they mean the times when a system like ChatGPT or Llama gives an answer that sounds confident and detailed, but is actually wrong. The paper explains that this isn’t really like a human hallucination (seeing or hearing something unreal), but more like a confident guess that turns out to be false. The term just stuck.
For example, if you ask about someone’s birthday, the AI might confidently say “March 7th” even if that’s not the truth. It doesn’t say “I don’t know” — it just outputs something that looks like an answer.
Why does this happen?

The authors argue that hallucinations aren’t mysterious. They are the natural result of how AI is trained and tested.
During training (pretraining stage)
- Models learn patterns from huge amounts of text. Even if the text was perfectly clean, the statistical training process itself would still produce errors. The paper compares this to a kind of classification problem in machine learning where errors are expected.
- Some errors are unavoidable when the model doesn’t have enough information. For example, if a rare fact like “a random person’s birthday” only appeared once in the training data, the model can’t learn a reliable pattern. The authors describe this as “singleton rate” — if facts only appear once, models will often get them wrong.
- So at this stage, hallucinations come from the statistical limits of training.
After training (post-training stage)
- Models are refined to be more useful. This stage often uses methods like reinforcement learning from human feedback.
- But here’s the key point: the way we test and score the models encourages them to guess. Most evaluations treat answers in a strict binary way: either correct (1 point) or incorrect (0 points). Saying “I don’t know” also gets 0 points.
- That means guessing is always better than admitting uncertainty, because at least a guess has a chance of being correct.
- The authors compare this to students in an exam. If you get no marks for leaving an answer blank, but you might get marks for guessing, then you will always guess. Even if you don’t really know.
Why do hallucinations persist?
The authors call this an “epidemic of penalizing uncertainty.” Since nearly all the popular benchmarks and leaderboards for AI models use binary scoring, models are rewarded for guessing. And models that guess more will look better on those benchmarks than models that honestly say “I don’t know.”
So the cycle continues:
- Training produces some natural errors.
- Testing rewards guessing instead of honesty.
- Models that bluff more often rise to the top of leaderboards.
This explains why even the newest and best models still hallucinate.
A look at benchmarks
The paper shows a table of well-known AI benchmarks like GPQA, MMLU, Omni-MATH, BBH, and SWE-bench. Almost all of them score answers in a binary way. Only one (WildBench) gives partial credit for “I don’t know” answers.
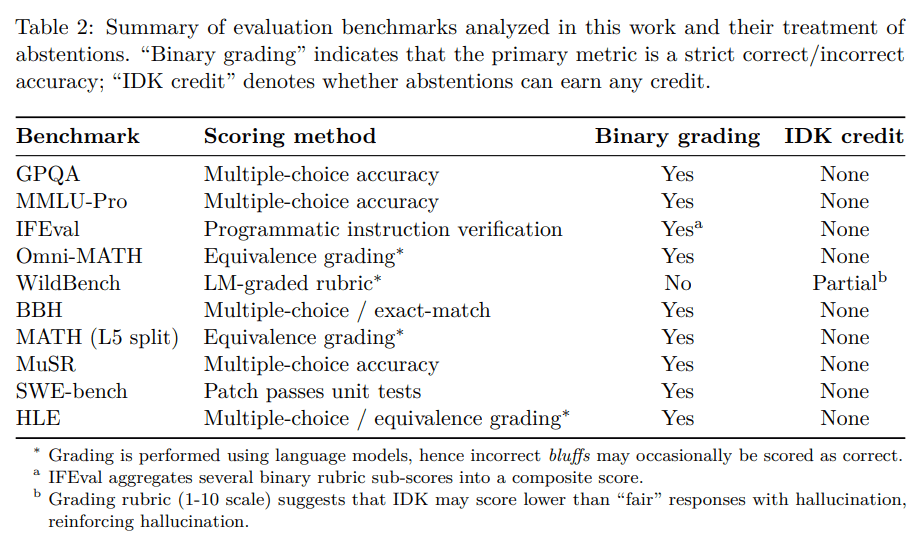
This shows how deeply built-in the problem is. The testing culture itself pushes models to act like confident guessers.
The analogy to exams
One of the clearest comparisons in the paper is to exams that humans take. In some exams, wrong answers are penalized (for example, you lose points for a wrong guess). That discourages random guessing. In other exams, you only get points for correct answers, and blanks get nothing. In those cases, students are encouraged to guess even when they don’t know.
AI models are treated like students in the second kind of exam. Saying “I don’t know” is the same as leaving it blank. So they learn to always try a guess.
What the paper suggests
The authors don’t propose creating new “hallucination benchmarks.” Instead, they suggest modifying existing evaluations so that they don’t punish uncertainty. For example, introducing explicit confidence targets. That means the instructions could say: “Only answer if you’re at least 75% sure. Otherwise say ‘I don’t know.’” In that setup, guessing would sometimes hurt the score, and saying “I don’t know” would be the rational choice when uncertain.
This way, models wouldn’t be trapped in permanent “test-taking” mode where guessing is always the best option.
Key takeaway I noted
Hallucinations are not strange side-effects. They are expected, given the math of training, and then amplified by the way we evaluate and score models. The system itself creates and rewards this behavior.
It reminded me of something simple: incentives shape behavior. If the incentives reward bluffing, you’ll get bluffing. If the incentives reward honesty, you’ll get more honesty. The models don’t choose — they adapt to the system they’re placed in.
My understanding so far
- AI models sometimes “make things up” because training on language data cannot avoid certain types of error.
- After training, evaluations reinforce the problem by scoring in a way that punishes saying “I don’t know.”
- Because of this, models guess when unsure. That’s why they often sound confident even when they’re wrong.
- Fixing this isn’t about more hallucination testing. It’s about changing the scoring rules of the main benchmarks.
Why this matters (in my own words)
If AI is going to be used in serious settings, trust matters. Trust comes from not just being right, but also from knowing when you don’t know. This paper helped me see that the current way we test AI doesn’t encourage that. Instead, it encourages bluffing.
That’s what I learned from reading Why Language Models Hallucinate. It’s not a full technical summary, but these are the main points I could gather in hopefully a plain language.

Leave a comment