Back in the early days, SEO was simpler. You put your keyword in the title, repeated it in the headings and body, and it worked. Google at that point was closer to a dictionary lookup than anything else.
Now things are different. Google tries to understand meaning, not just exact words. If someone searches “cheap shoes”, it also understands they might mean “affordable sneakers” or “budget footwear.”
That change comes from something called embeddings. I’m still wrapping my head around them, but the idea is that text gets turned into mathematical fingerprints (vectors). Instead of asking “do these words match?” Google asks “do these two fingerprints point in the same direction?”
I’m not the first to look into this. Research like SBERT (Reimers & Gurevych, 2019), benchmarks like MTEB (Hugging Face leaderboard), and use cases like retrieval-augmented generation (RAG) all show how important embeddings are.
For me, the point of this post isn’t to be an expert guide — it’s just me experimenting, trying to see how this works in practice, and sharing what I learned along the way.
My inspiration
I came across Dan Petrovic’s blog (dejan.ai) where he explained EmbeddingGemma.

He broke it down simply:
- Gemini = Google’s giant AI powering advanced search.
- Gemma = its open-source smaller sibling.
- EmbeddingGemma = the version tuned for semantic similarity.
Dan’s team does impressive stuff with this — like query fan-out (taking one query and generating many related variations) and intent clustering. I knew I wouldn’t reach that level (yet), but it made me curious to try a smaller experiment myself.
What even is EmbeddingGemma?

EmbeddingGemma is Google’s compact, open-source embedding model. It is basically a way to turn text into math so machines can compare meaning. Here’s what stuck with me while reading about it:
- Compact: 308M parameters — small enough to run on a laptop.
- Multilingual: Works in 100+ languages, tested in MMTEB (2025 paper).
- Detailed vectors: Each sentence becomes a 768-number fingerprint of meaning.
- Shrinkable: With Matryoshka learning (NeurIPS 2022), you can shrink those vectors down without losing too much accuracy.
- Proven benchmarks: It scores well on MTEB for tasks like retrieval, clustering, and classification (Hugging Face blog).
Why it matters for SEO (at least in my eyes): this feels like a glimpse into how Google might really be comparing queries to content — not by words on the page, but by meaning.
My setup (a.k.a. How I made this run without breaking my laptop)
Here’s how I got it running:
- Installed Ollama (lets you run models locally).
ollama pull embeddinggemma - Made sure Python was installed.
- Picked my guinea pig content: my article Why AI Makes Things Up.
- Queries I tested:
- “why language models hallucinate”
- “why language models hallucinate openai”
- “why ai hallucinates”
- “why ai makes things up”
I wrote two small scripts:
- Whole article embedding: gives one score for the entire article.
- Section embeddings: scores each header section separately.
I had no idea which would be more useful — I just wanted to see.
Understanding the scores
When you run the script, you don’t get “yes” or “no.” You get similarity scores, based on something called cosine similarity.
Here’s how I understood it:
- If two vectors point in the same direction, score is close to 1 (identical meaning).
- If they’re at a right angle, score is 0 (unrelated).
- If they point in opposite directions, score is -1 (opposites).
In practice, most scores land between 0.0 and 0.7:
- 0.5–0.7 → Strong match (pretty close in meaning).
- 0.3–0.5 → Moderate match (related but not exact).
- Below 0.3 → Weak (not really relevant).
Academic research validates cosine similarity:
- SBERT (Reimers & Gurevych, 2019): Showed cosine similarity between sentence embeddings strongly correlates with human similarity judgments (arxiv.org).
- GEM 2022 (Zhou et al.): Found SBERT’s cosine similarity aligns most closely with human semantic ratings (aclanthology.org).
One more thing I noticed:
- Whole article embeddings flatten everything into one vector, so scores are usually vague.
- Section embeddings look at each heading separately, which makes the differences much clearer.
Outputs from my run
Here’s what I got when I compared my article with the four queries:
Whole article embedding:

Observation: everything is “kind of” relevant, but you don’t get much insight into which part of the article is doing the work.
Section embeddings:
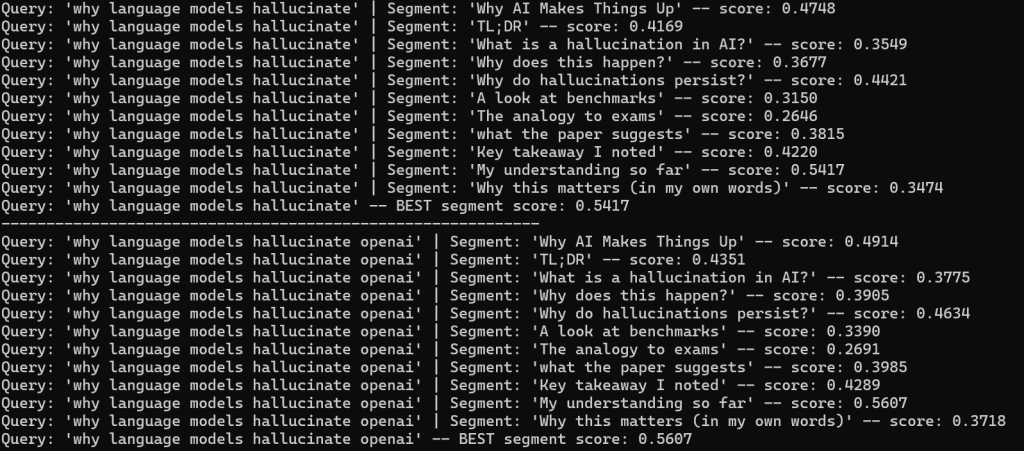
This felt way more useful. Some sections clearly matched queries better than others.
What SEOs can do with embedding scores
- Audit content by headers/sections, not just whole page. Queries map to sections. Some sections pull their weight; others don’t.
- Fill gaps. If a query scores below ~0.35 everywhere, you’re missing coverage.
- Fan out queries. Use embeddings to expand seed queries, then test if your content answers them.
- Split winners. If one H2 scores for multiple queries, maybe it deserves its own page.
- Scale it. Automate this, export CSV (Query | Section | Score | Suggested Action), hand it to your content team.
My Takeaway
Google doesn’t just match words, it compares vectors.
This small test helped me see how embeddings and cosine similarity can highlight which parts of content actually match a query.
I’m not an expert — just experimenting and learning. But even with a simple setup (a laptop, Ollama, and some Python), I got a glimpse of how Google might compare meaning instead of just words.

Leave a comment